Datasets in mofdscribe#
StructureDatasets#
The main class of datasets that mofdscribe currently provides is StructureDataset.
They basically act as a wrapper around a collection of pymatgen.core.Structure objects, but also provide some additional data such as pre-computed features and some labels.
Why use StructureDatasets?#
The main reason for using StructureDataset is to provide a unified interface to different datasets (making it easy to reuse code for different datasets). That unified interface allows to use the splitters implemented in mofdscribe.
However, StructureDataset also provides some other conveniences
hashes for de-duplication are automatically computed if not available
additional metadata (e.g. publication years) is provided (if available)
you do not need to worry about maintaining folders of different versions yourself — mofdscribe will handle the version management for you, and you can be sure that other users of mofdscribe will use the same dataset
makes it pretty easy to visualize a structure for a given entry
you only need to download the data once
Where is the data?
The data will be downloaded into a ~/.data/mofdscribe folder. If you run into issues, you can consider deleting the folder corresponding to a specific dataset to trigger a re-download.
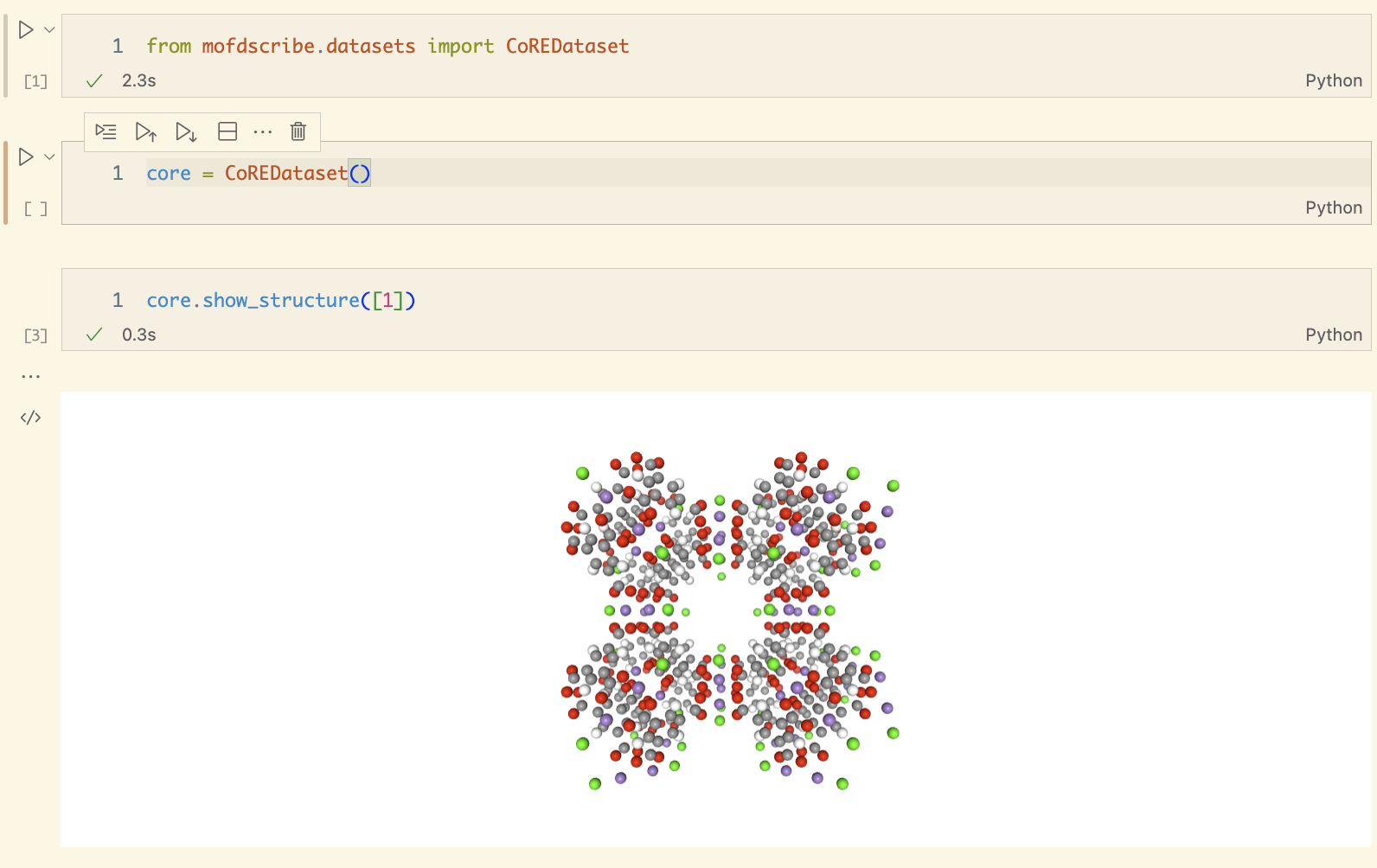
Visualizing structures
If you’re in a notebook you can simply call show_structure() to look at a structure.
This can be handy if you want to explore extremes of a dataset (however, also here keep in mind that looking at the full dataset before splitting is considered data leakage).
Constructing a subset
For some applications (e.g., nested cross-validation) you want to construct a subset of the dataset. You can do so easily using the get_subset() function.
Dataframe conventions
When we also provide a pandas.DataFrame for the dataset, we follow these conventions:
dataframe is accessible via the
_dfattributeoutputs of simulations are prefixed with
outputfeatures are prefixed with
featuresadditional infos such as hashes are prefixed with
infoif there are multiple flavors of dataset, we provide boolean masks under columns prefixed with
flavor